


26年前的古董Win98电脑成功运行大语言模型:搭载奔腾II处理器、128MB内存 普及AI愿景实现
 摘要:
一个名为 EXO Labs 的组织在社交媒体上发布了一段视频,展示了一台运行 Windows 98 系统的 26 年高龄的奔腾 II 电脑成功运行大型语言模型(LLM)的情形。这台...
摘要:
一个名为 EXO Labs 的组织在社交媒体上发布了一段视频,展示了一台运行 Windows 98 系统的 26 年高龄的奔腾 II 电脑成功运行大型语言模型(LLM)的情形。这台... 一个名为 EXO Labs 的组织在社交媒体上发布了一段视频,展示了一台运行 Windows 98 系统的 26 年高龄的奔腾 II 电脑成功运行大型语言模型(LLM)的情形。这台电脑拥有 128MB 内存和 350MHz 的处理器。EXO Labs 在其博客上进一步阐述了这个项目的细节及其“普及人工智能”的愿景。
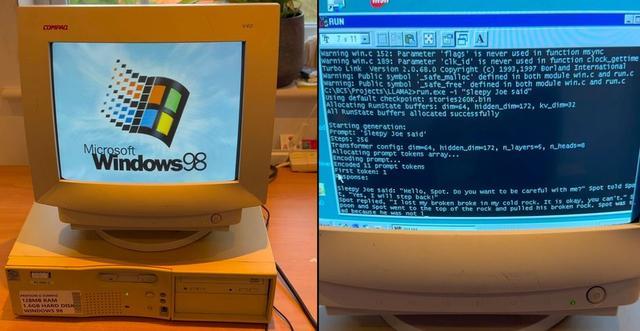
视频中,这台古老的 Elonex 奔腾 II 电脑启动 Windows 98 后,运行了基于 Andrej Karpathy 的 Llama2.c 开发的定制纯 C 推理引擎,并生成了一个关于“Sleepy Joe”的故事。整个过程运行流畅,故事生成速度也相当可观。
EXO Labs 由牛津大学的研究人员和工程师组成,于今年 9 月正式对外亮相,其使命是“普及人工智能”。该组织认为,少数大型企业控制人工智能会对文化、真相以及社会其他基本方面造成负面影响。因此,他们希望构建开放的基础设施,以训练前沿模型,并使任何人都能在任何设备上运行它们。此次在 Windows 98 上运行 LLM 的壮举正是对这一理念的有力证明。
为了实现这一目标,EXO Labs 从 eBay 上购得了一台老式 Windows 98 电脑,并通过以太网端口使用 FTP 完成了文件传输。更大的挑战在于为 Windows 98 编译现代代码,但他们找到了 Andrej Karpathy 的 llama2.c 工具。借助这一资源以及 Borland C++ 5.02 IDE 和编译器,EXO Labs 成功将代码编译成可在 Windows 98 上运行的可执行文件,并在 GitHub 上公开了最终代码。
Alex Cheema 特别感谢了 Andrej Karpathy 的代码,并对其性能赞叹不已。使用基于 Llama 架构的 26 万参数 LLM 时,在 Windows 98 上实现了每秒 35.9 个 token 的生成速度。Karpathy 曾任特斯拉人工智能主管,也是 OpenAI 的创始团队成员之一。
虽然 26 万参数的 LLM 规模较小,但在这台古老的 350MHz 单核电脑上运行速度相当不错。使用 1500 万参数的 LLM 时,生成速度略高于每秒 1 个 token。而使用 Llama 3.2 10 亿参数模型时,速度则非常缓慢,仅为每秒 0.0093 个 token。
EXO Labs 的目标远不止于在 Windows 98 机器上运行 LLM。他们在博客文章中进一步阐述了其对未来的展望,并希望通过 BitNet 实现人工智能的普及。BitNet 是一种使用三元权重的 transformer 架构,使用这种架构,一个 70 亿参数的模型只需要 1.38GB 的存储空间。这对于一台 26 年前的奔腾 II 来说可能仍然有些吃力,但对于现代硬件甚至十年前的设备来说,都非常轻量级。
此外,BitNet 是 CPU 优先的,避免了对昂贵 GPU 的依赖。据称这种类型的模型比全精度模型效率高 50%,并且可以在单个 CPU 上以人类阅读速度(约每秒 5 到 7 个 token)运行一个 1000 亿参数的模型。







